Engineering Article
How I Built an Offline Irregular Sudoku Generator for Android
From connected region layouts to curated puzzle banks
In my Android Sudoku app, I did not want irregular Sudoku to feel like a novelty mode layered on top of a classic generator. I wanted it to hold up as real product content, with layouts that looked deliberate, puzzles that stayed uniquely solvable, and a generation system I could trust.
That made irregular Sudoku a much harder engineering problem than classic Sudoku. In the classic case, the 9x9 board already comes with a fixed box structure. In the irregular case, the system first has to generate the board structure itself: nine connected regions of nine cells each, before it can even begin generating a puzzle.
So the job was not just to remove clues from a solved grid. It was to build an offline workflow that could generate valid irregular layouts, fill them with complete solution grids, remove clues while preserving uniqueness, and curate the results into a puzzle bank.
This article is about that system. It is not a claim that irregular Sudoku generation has been "solved" in some universal sense. It is a practical engineering story about building content for a real product rather than a one-off script or experiment.
Why irregular Sudoku is a harder generation problem
Classic Sudoku benefits from a fixed structure. The board is always divided into the same nine 3x3 boxes. That removes one entire layer of complexity from the problem.
Irregular Sudoku does not have that luxury.
Before generating a single puzzle, the system first needs a valid layout - a partition of the 9x9 board into nine connected regions of nine cells each. Those regions replace the standard 3x3 boxes. If the layout is poor, the puzzle can become visually messy, awkward to solve, or unpleasant to ship as part of a curated bank.
So the problem is not just "generate a Sudoku puzzle." It is really four linked problems:
- generate a valid irregular region layout
- fill that layout with a complete valid solution grid
- remove clues while preserving uniqueness
- filter and curate the result into a usable puzzle bank
That last step matters more than it sounds. Generating a puzzle is easier than generating a collection that feels intentional.
Generating irregular layouts
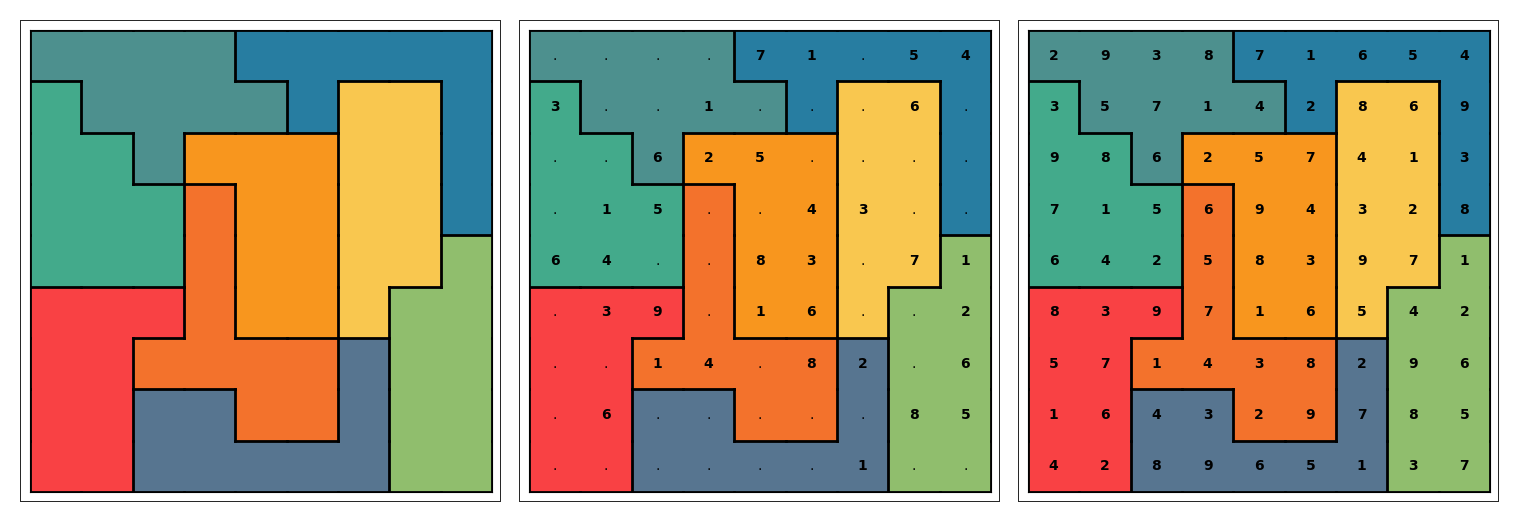
The first stage is region generation.
The layout generator starts with nine seed cells and grows them into nine full regions. Each region must end up with exactly nine cells, and every region must remain orthogonally connected. That connectivity requirement is non-negotiable. A region cannot split into disconnected islands.
The growth process is competitive. Regions expand into neighboring empty cells, but not uniformly. The generator uses a cohesion bias so that growth tends to favor shapes that stay more locally coherent instead of spreading too chaotically across the board. That does not guarantee beauty in some abstract sense, but it does help avoid layouts that feel random or visually broken.
The initial intuition for this part of the generator came from competitive growth in natural systems: multiple regions expanding into available space while preserving their own internal cohesion. The final implementation is a practical heuristic model rather than a literal biological simulation, but that starting point helped shape the generator's growth-and-contest structure.
There is also explicit connectivity protection during displacement decisions. If a move would damage the connectedness of a region, it is rejected. Connectivity checks are handled directly rather than assumed.
Irregular Sudoku layout quality affects everything downstream. A weak layout can still be technically valid, but validity alone is not enough when you are building puzzles for an actual app.
Filling a valid solution grid
Once a valid irregular layout exists, the next step is building a complete solved board that respects row, column, and irregular-region constraints.
That part relies on a backtracking solver, but the implementation is not naive.
Two choices matter here:
- bitmask-based bookkeeping
- minimum remaining values (MRV) cell selection
Bitmasks make legality checks cheap. Instead of repeatedly scanning rows, columns, and regions from scratch, the solver tracks used digits compactly and updates that state incrementally. That keeps candidate calculation fast and reduces overhead during deep search.
Minimum remaining values (MRV) is the other major lever. This is a standard search heuristic that picks the most constrained empty cell first, meaning the cell with the fewest legal candidates. When the solver chooses the next empty cell, it does not just pick the next one in reading order. It chooses the cell with the fewest legal candidates. In practice, that cuts down the branching factor and avoids a lot of wasted search.
Those optimizations matter because solving is not a one-time cost. The solver gets reused throughout generation, especially when clue removal repeatedly asks the more important question: does this partial puzzle still have a unique solution?
Turning a full grid into a puzzle
A completed solution grid is not yet a puzzle. The generator still has to remove clues.
You can describe clue removal as "delete numbers until uniqueness breaks," but that hides the real engineering detail: the process is controlled, competitive, and repeatedly validated.
In my irregular generator, clue removal follows a competitive pattern rather than a flat random deletion pass. Candidate removals are not treated as equal. The system keeps track of local removal dynamics and strengthens neighbors of successful removals, which nudges the process toward more coherent clue-loss patterns instead of uniform random clue stripping.
Every tentative removal is checked against uniqueness. The generator uses a fast solver that counts solutions only up to a small cap, because once a second solution exists, that candidate is already disqualified. There is no value in exploring beyond that point. This early-exit behavior matters a lot, because clue removal spends more time rejecting bad removals than accepting good ones.
There is also a stagnation limit in the removal loop. That prevents the generator from burning unlimited time chasing a cleaner puzzle when progress has effectively stopped. In production tooling, that kind of cap is what separates a generator that works in theory from one that remains usable at scale.
Uniqueness is the real constraint
Many people think difficulty is the hard part of Sudoku generation. In practice, uniqueness is the line you cannot cross.
Once clues start disappearing, the search space opens up quickly. It is easy to create a puzzle that looks sparse and interesting but admits multiple solutions. That is useless for shipping.
So uniqueness checking becomes the strict gate behind the whole removal stage. A removal is only accepted if the puzzle remains uniquely solvable. Otherwise it is rolled back and the generator moves on.
In irregular Sudoku, this matters even more because the region structure itself is part of the puzzle identity. A generator cannot rely on classic assumptions and hope the rest will behave. The region map, the completed grid, and the clue pattern all interact.
Difficulty in the generation pipeline
One place where technical writing can go wrong is pretending that solver metrics and human difficulty are the same thing. They are not.
The offline generation tooling can use search-side metrics during candidate generation and filtering. Those metrics are useful operationally. They can help separate weak candidates from stronger ones and support bank building. But they are still proxies derived from solver behavior, not a universal measure of how a human will experience the puzzle.
Final shipped difficulty is aligned more closely with the app's human-oriented difficulty rater. That rater is based on the level of solving techniques required to complete a puzzle. For example, a puzzle that can be solved entirely through singles, such as naked singles and hidden singles, belongs in the easiest tier. Harder puzzles require progressively stronger techniques.
The full rating system deserves its own write-up, because it applies across variants and is a substantial part of the app on its own. For this article, the important point is simpler: irregular puzzle generation and bank building are not judged only by search cost. They are expected to align with player-facing solving difficulty as well.
That is less neat than pretending there is one perfect difficulty equation, but it is much more credible and much closer to how real production systems evolve.
Metadata and traceability
One part of the workflow that matters in practice is metadata. Once a puzzle has been generated and accepted, the important question is usually not whether the exact run can be recreated from scratch. The important question is whether the result is easy to inspect, organize, and maintain.
Each generated candidate can carry metadata such as layout identity, puzzle data, solution data, and generation-side metrics. That matters when reviewing outputs, deduplicating them, assigning stable identifiers, or applying later curation passes.
This is not the glamorous side of puzzle generation, but it is one of the parts that makes the system usable over time. A generator that emits opaque results is hard to manage. A generator that emits traceable artifacts is much easier to maintain and evolve.
From generation to shipped content

The most important architectural choice in this project was keeping irregular generation as an offline workflow rather than trying to do all of it on demand inside the app.
That has several advantages. The generator can spend more time exploring candidates, rejecting weak outputs, and preserving quality. The shipped app stays simpler because it consumes banked content instead of doing the heaviest generation work during gameplay. The bank can also be curated, audited, deduplicated, and rated before it ever reaches the user.
That is a better fit for the kind of product I wanted to build. The player should see a clean puzzle and a smooth experience. The generation complexity belongs behind the scenes.
What building this taught me
The biggest lesson from this work is that Sudoku generation is not just about solving constraints. It is about building a reliable pipeline.
Any one part of the system can sound manageable in isolation:
- grow connected irregular regions
- solve a full board
- remove clues
- check uniqueness
- bucket results
- store metadata
But stitching those parts together into something disciplined enough to produce a real puzzle bank is the actual challenge.
You have to care about structure, runtime behavior, curation quality, and failure handling at the same time. That is where the engineering lives.
Irregular Sudoku made that especially clear. It adds one more structural degree of freedom than classic Sudoku, and that one change propagates through the entire pipeline.
About the app
This generator was built for my Android game, Sudoku, where irregular Sudoku ships as part of a broader set of puzzle variants. The goal was not just to make the variant possible. It was to make it feel native to the product, with curated puzzle content and a clean mobile play experience.
If you arrive at this article from the engineering side, the app is where this workflow becomes visible as a player-facing feature rather than a backend tool.
Closing
From the player's side, irregular Sudoku is just another variant on the menu.
From the engineering side, it is a much more demanding content-generation problem than classic Sudoku. You need valid connected layouts, fast solving, uniqueness-preserving clue removal, and enough filtering discipline to keep weak outputs out of the shipped bank.
That is what this generator was built to do.
The result is not just "a way to make puzzles." It is an offline production workflow for building irregular Sudoku content that can be reviewed, curated, and shipped with confidence.
If you are building puzzle systems, that distinction matters. Generating content is one thing. Generating content you can trust in a real product is something else.